
Défi nous a été donné de concevoir et réaliser en 4 semaines une nouvelle application sur un nouveau domaine fonctionnel : l’analyse de la réputation des marques auprès des moteurs LLM (Large Languages Models). Les Directions Marketing et Commerciale avaient déjà des premiers rendez-vous planifiés et voulaient montrer une application riche, fonctionnelle et ergonomique, sur la base d’un premier cahier des charges. L’enjeu était donc de respecter le cahier des charges, dans les délais, tout en proposant une méthodologie d’étude de la réputation des marques et en sachant produire des premières analyses pour les marques que les Directions allaient rencontrer…
Sachant que nous n’allions manipuler aucune donnée sensible et itérer rapidement sur les fonctionnalités et les écrans, j’ai profité de l’occasion pour demander à expérimenter à titre professionnel le vibe coding, c’est-à-dire le développement d’application uniquement à partir de conversations avec une IA générative.
Je l’avais déjà expérimenté à titre personnel plusieurs mois auparavant avec Bolt.new. Cette fois, j’allais le faire, en équipe et dans un contexte contraint, avec la solution de Google : Firebase Studio. Je vous propose ici mon retour d’expérience. Ce n’est pas l’exposé d’une méthode absolue mais cela devrait cependant vous inspirer pour construire votre propre pratique du vibe coding.

Miser sur le vibe coding pour imaginer une application au fur et à mesure
Le gain immédiat du vibe coding est de pouvoir imaginer l’application au fur et à mesure.
Le terme vibe coding aurait été inventé en février 2025 par Andrej Karpathy, cofondateur d’OpenAI, qui l’a décrit comme « un nouveau type de codage où vous vous abandonnez complètement aux vibes, embrassez les exponentielles, et oubliez que le code même existe. »
Selon lui, le vibe coding est une approche de développement logiciel basée sur les chatbots où le développeur décrit un projet ou une tâche à un grand modèle de langage (LLM), qui génère ensuite du code basé sur cette demande. Le développeur n’examine plus le code généré, mais utilise uniquement les outils et les résultats d’exécution pour l’évaluer et demander des améliorations au LLM. Contrairement au codage assisté ou à la programmation en binôme, le développeur humain évite l’examen du code, accepte les suggestions de l’IA sans révision humaine, et se concentre plus sur l’expérimentation itérative que sur la correction ou la structure du code.
« Le vibe coding est un nouveau type de codage où vous vous abandonnez complètement aux vibes, embrassez les exponentielles, et oubliez que le code même existe. »
Andrej Karpathy, cofondateur d’OpenAI
De notre côté, il a en effet été possible d’itérer et d’imaginer l’application au fur et à mesure que nous en parlions entre nous. Pourtant, il fallut très rapidement, construire des techniques pour sécuriser la qualité du code applicatif. La promesse du vibe coding semble donc un peu exagérée, à ce jour : le vibe coding se configure et s’exécute avec précautions.
Mais le gain de temps reste considérable (la consommation de tokens aussi !). A la condition de le mettre entre les mains des développeurs, de l’encadrer par des règles et des exemples et de le spécialiser sur certaines tâches du projet, le vibe coding apporte, selon moi, une réelle plus-value.
4 semaines pour expérimenter des techniques d’encadrement
Notre expérimentation a été un succès puisque que le cahier des charges a été respecté (nous sommes allés au-delà) et que les délais ont été tenus à un coût faible. L’IA générative a généré 85% du code et l’application repose sur les briques suivantes :
- Frontend : React avec Vite et TypeScript.
- Backend : Node.js avec Express.
- Base de données : PostgreSQL (Google Cloud)
- Communication : API RESTful
- LLM : Google AI Studio
- Versionning : Github (devenu GitLab dans les instances sécurisées d’Orange Business en fin de projet)
Les 15% restants sont du code Python et la configuration de tableaux de bord sous Looker Studio (ces tableaux furent finalement abandonnés pour simplifier l’architecture du prototype).
Semaine 1
Avec la plateforme Firebase Studio, au commencement, les idées initiales, les corrections et les changements d’avis sont assez rapides à implémenter : on obtient facilement une première IHM propre, sans avoir à se poser trop de questions. On travaille à partir de maquettes et de user stories
Les premiers rendus sont tout autant encourageants que les nombreux d’outils de maquettage, boostés à l’IA générative, à l’exception qu’ici, l’application fonctionne réellement.
Semaine 2
A partir d’un certain niveau de complexité, l’enrichissement fonctionnel et le maintien d’une cohérence globale deviennent plus difficiles. Les risques de régressions, de perte de fonctionnalités et d’incohérences architecturales s’élèvent. Chez nous, dès la 2ème semaine, il est devenu indispensable d’expérimenter et de déployer toute technique ayant démontré sa capacité à « sécuriser » la qualité du projet.
Semaine 3
A compter de la 3ème semaine, j’ai laissé tomber le principe du vibe coding consistant à tout demander à l’IA générative. Même pour un intervenant disposant d’un niveau technique de base, comme moi, il devenait plus rapide et plus efficace de modifier certains éléments à la main plutôt que de passer du temps à expliquer à l’IA Générative ce qu’il fallait modifier. Concrètement, il était plus efficace de modifier moi-même les libellés et titres dans les écrans, les titres des logs, certaines parties de requêtes SQL ou de codes (exemple : le choix des couleurs).
C’est aussi à compter de la 3ème semaine que j’ai expérimenté le travail collaboratif entre plusieurs instances de Firebase Studio. Il a suffi que les développeurs de l’équipe m’expliquent comment ils synchronisaient leurs propres travaux pour le reproduire avec 3 instances Firebase Studio spécialisées et accélérer encore les travaux.
Semaine 4
A compter de la 4ème semaine, toutes les techniques décrites plus bas étaient en place, avec une documentation mise à jour à l’issue de chaque nouvelle fonctionnalité.
L’IA générative a commencé à être plus stable, avec beaucoup moins de régressions. J’ai cependant pris une nouvelle habitude : recommencer une nouvelle conversation dès que l’IA Générative baissait en qualité (voir plus bas).
Problèmes rencontrés et solutions expérimentées
1. Créativité destructrice
Problème #1 : l’IA possède une tendance naturelle à « améliorer » ou « optimiser » le code existant, même quand ce n’est pas demandé. Elle commente des lignes, reformate le code, ou « nettoie » ce qu’elle perçoit comme du code redondant.
Problème #2 : dans Firebase Studio, l’IA ne modifie pas un fichier, elle le charge en mémoire et le réécrit en totalité. Et ce faisant, elle peut très bien « oublier » des parties du code lors de la réécriture d’un fichier, remplaçant l’intégralité du contenu par seulement la partie modifiée.
Impact : Perte de fonctionnalités, introduction de bugs, corruption progressive de la base de code, effacement des commentaires…
Solution expérimentée #1 : Firebase Studio ne met aucun fichier à jour, sans la validation de l’utilisateur. Il est possible de consulter la mise à jour proposée et de voir clairement ce que l’IA veut supprimer et ajouter. Il ne faut donc jamais valider la mise à jour d’un fichier sans avoir préalablement consulté la mise à jour proposée et ne pas hésiter à la refuser en expliquant pourquoi. Lorsque la mise à jour est simple, il est aussi possible de s’en inspirer et de l’appliquer soi-même.
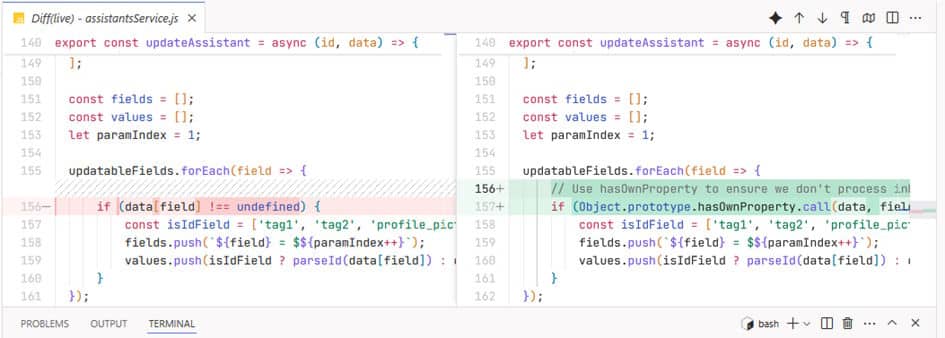
2. Hallucination récurrente
Problème #3 : L’IA « hallucine » avec confiance. Elle invente des chemins de fichiers, suppose l’existence de fonctions, et construit des dépendances sur des éléments fictifs.
Problème #4 : L’IA ne vérifie pas toujours ce qu’elle dit, elle se fie à sa mémoire, parfois même lorsqu’on lui demande de vérifier explicitement.
Impact : erreurs récurrentes, auto-critique défaillante, usages des tests de non-régression pas toujours efficace.
Solution expérimentée #2 : Ajouter des règles de fonctionnement strictes dans son fichier .idx/airules.md. Ce fichier consigne des règles que l’IA doit respecter à chaque fois. Nous avions fait rédiger au fur et à mesure à l’IA des problèmes rencontrés plusieurs « principes » et « dogmes » dans ce fichier pour la forcer à être plus précise dans son travail. Les principes ne sont pas toujours respectés mais si je devais commencer un autre projet, je reprendrais dès le début les mêmes règles.
Solution expérimentée #3 : construire plusieurs alias pour simplifier les chemins pour le frontend et le backend. Ajouter explicitement la mention de ces alias et leur usage obligatoire en commentaires au début des fichiers. Puisque l’IA relit toujours les fichiers avant de les modifier, cela lui donne des consignes qu’elle semble mieux respecter que les règles du fichier idx/airules.md. Cette solution a été expérimentée sur un module complexe en cours de développement et nous n’avons eu plus eu de problème de chemin.
3. Pas de capitalisation
Problème #5 : sauf contre-ordre explicite de la part de l’utilisateur, l’IA réinvente presque chaque fois ses codes et ses raisonnements. Elle peut diversifier ses manières de coder, répéter les mêmes erreurs, partir dans une direction d’architecture ou de logique totalement différente du reste de l’application …
Problème #6 : l’IA ne respecte pas d’architecture type ni de patterns techniques récurrent, stable. Pour chaque nouvelle fonctionnalité, elle peut réinventer une logique différente. Lorsqu’elle recherche des fichiers déjà existants, elle oublie fréquemment l’arborescence et la logique existante : elle peut aussi inventer des noms de fichiers, des composants UI ou des librairies qui n’existent pas dans l’application.
Impact : Perte de temps, perte de qualité, complexification croissante.
Solution expérimentée #4 : documenter au fur et à mesure des archétypes et forcer l’IA à s’y référer selon un principe « Répliquer ce qui existe, ne pas inventer ». Chaque nouveau développement doit démarrer par l’identification de l’archétype le plus proche.
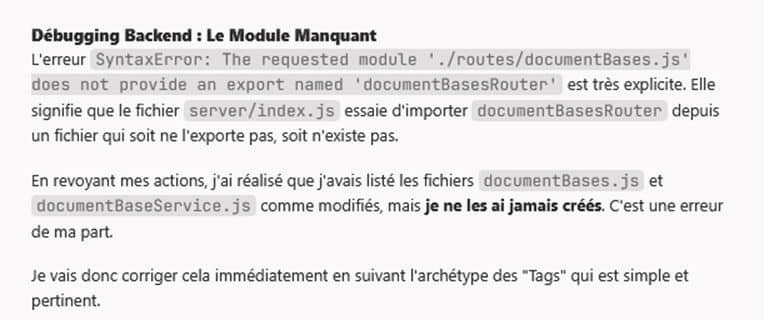
Solution expérimentée #5 : construire une bibliothèque de règles à respecter dans le fichier idx/airules.md puisqu’il est relu (normalement) chaque fois par l’IA générative. Par exemple :
- Les méthodes de travail obligatoires (Analyse → Validation → Exécution → Vérification)
- Les principes de codage (reconstruction intégrale, protection de l’existant, validation par diff) –> pas toujours respectés lors de courts délais !
4. Oubli de l’objectif cible
Problème # 7 : on peut dialoguer longuement avec l’IA générative pour affiner une spécification ou un plan d’actions détaillé. Mais il ne faut pas se fier à elle pour s’en souvenir longtemps et respecter absolument ce qui a été convenu, dès lors que c’est un peu long ou complexe.
Impact : Perte de temps, oubli des spécifications, dérive fonctionnelle.
Solution expérimentée #5 : finaliser la réflexion en demandant à l’IA de générer un fichier de spécifications, sous le contrôle qualité de l’utilisateur. Puis demander à l’IA, pendant l’avancement des travaux de mettre à jour par enrichissement (jamais par effacement) ce fichier. Lors des conversations avec l’IA, lui demander régulièrement de relire le fichier (lui fournir le lien) pour la forcer à se souvenir du contexte.
Pour le développement de deux modules complexes (une double boucle d’appels à un service tiers avec un polling et un système de vectorisation et de RAG incluant textes et images), j’ai également exigé que le fichier rappelle les choix techniques, les fichiers et l’arborescence, les exemples d’input et d’output de certaines fonctions, etc.
Autres solutions expérimentées
1. Empêcher que les fichiers ne deviennent trop gros
A partir d’une certaine taille, la probabilité que l’IA générative réécrive un fichier avec des erreurs est très élevée. Elle met également beaucoup plus de temps à le lire à et à le corriger, sans parler de la consommation de tokens.
A l’inverse, si un module est fortement factorisé avec de nombreux composants, les erreurs dans la rédaction des imports et des chemins deviennent fréquentes (mais on dirait qu’en utilisant des alias documentés directement dans les fichiers, les erreurs se réduisent nettement).
2. Cloisonner les expérimentations complexes
L’IA n’a aucune mémoire des usages des fichiers et des fonctions. Si vous développez un nouveau module, en capitalisant sur des fonctions déjà utilisées ailleurs (hooks, services divers) … elle n’aura aucun scrupule à modifier, voire à effacer des scripts existants pour le besoin du module en cours, sans tenir compte des impacts.
Pour développer des modules complexes, nous avons donc dû imaginer selon les cas un cloisonnement drastique des services, puis des fichiers, puis de l’arborescence !!
Une autre option technique aurait été de verrouiller les fichiers pour interdire toute mise à jour, cela fonctionne très bien.
3. Recommencer une nouvelle conversation
Lorsque l’IA ne semble plus comprendre ce que l’on veut, ne plus respecter les consignes, l’architecture générale ou les patterns techniques, ou que cela devient laborieux, il vaut mieux arrêter la conversation.
Le mieux dans ce cas-là est de demander une synthèse détaillée de la situation puis commençons une nouvelle conversation en rappelant à nouveau les fondamentaux du projet et en demandant une analyse critique de la situation. C’est un peu comme si nous discutions avec un nouvel intervenant IA qui pourra recommencer à avoir un regard lucide et critique sur la situation.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn.














Commentaire (0)
Votre adresse de messagerie est uniquement utilisée par Orange Business, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Orange Business en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.