
On continue notre série d’articles dédiée à Data Rider, le projet de circuit de voitures qui allie IoT et IA. C’est parti pour un retour d’expérience sur les défis rencontrés et les leçons apprises tout au long de ce processus et qui pourraient vous servir pour vos projets en entreprise !

[Data Rider] Booster Mario Kart à l’IoT et à l’IA – Etape 1 : collecter les données IoT en temps réel
Lire la suiteCet article est la suite du précédent : [DataRider] – REX Collecte de données IoT – Etape 1 : Initialisation d’une collecte de données. Nous avions alors vu la mise en place de notre collecte de données pour obtenir les résultats de courses de petites voitures électriques.
Aujourd’hui, nous allons présenter comment l’implémentation des étapes de transformation de la donnée dans l’outil ETL nous a fait repenser la façon de collecter nos données et modifier le format de la collecte. Nous allons également vous présenter les considérations à prendre en compte pour que les données en sortie de la partie IoT puissent être directement exploitables pour piloter la main mécanique pilotée par IA.
![[DataRider] REX Collecte de données IoT – Étape 2 : Étude des opérations ETL, défis et solutions pour une collecte efficace](https://perspective.orange-business.com/wp-content/uploads/2025/08/data-rider-et2-collecte-donnees-1024x512-1.jpg)
1. Rappel des données collectées
Au stade du projet dont nous parlons, nous collectons, grâce à des capteurs et une carte Arduino, les informations de localisation et de tension pour chacune des voitures :
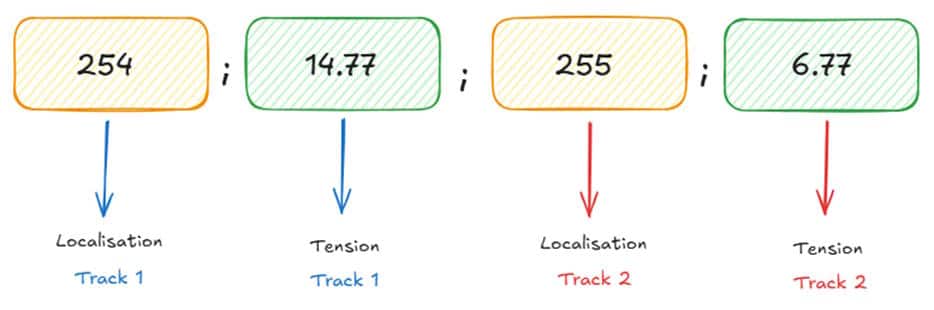
A chaque ligne de données est ajouté un timestamp, grâce à un script Python. Nous savons grâce au timestamp qu’une ligne de donnée est produite par l’Arduino toutes les 2 millisecondes environ.

2. Consolidation des données
Ces données ont besoin d’être consolidées par des informations complémentaires, et nous allons voir que cette étape n’a pas été aussi évidente qu’il n’y parait à mettre en place. Il y a notamment nécessité d’ajouter :
(1) Le numéro du tour, pour chacune des deux voitures, pendant une course
Par exemple, si une voiture a réalisé, depuis le début de la course, 3 tours et demi de circuit, son numéro de tour est « 3 ». Il passera à « 4 » quand elle repassera devant le premier capteur de localisation, c’est-à-dire le capteur situé sur la ligne de départ.
Pour retrouver cette information, il faut donc savoir combien de fois la voiture est passé devant le jalon « ligne de départ », de valeur « 254 », en remontant chronologiquement les données depuis le début de la course. On peut ensuite ajouter l’information sur la ligne concernée.
(2) La section de circuit sur laquelle se trouve la voiture
Si la voiture se trouve entre deux capteurs de position (deux jalons), alors sa localisation est à la valeur par défaut « 255 », ce qui ne permet pas réellement de savoir où elle se trouve. Pour avoir cette information, nous sommes, là encore, contraints de remonter chronologiquement les lignes de données jusqu’à trouver la valeur du dernier jalon passé. Cela permet ensuite d’ajouter, sur la ligne de données, le dernier jalon franchi, pour directement savoir sur quelle portion de circuit la voiture se trouve quand on regarde une ligne de données.
(3) D’autres informations qui sont des transformations sur les colonnes
Il s’agit par exemple de différences (soustraction) entre des valeurs pour recalibrer les valeurs de tension, de multiplications sur des colonnes pour obtenir les unités voulues…
Le schéma suivant récapitule ce que l’on souhaite obtenir pour les points (1) et (2). La localisation de la voiture est une donnée réellement collectée, tandis que le numéro du tour et le dernier jalon franchi sont des données « construites » à partir de la donnée de localisation.
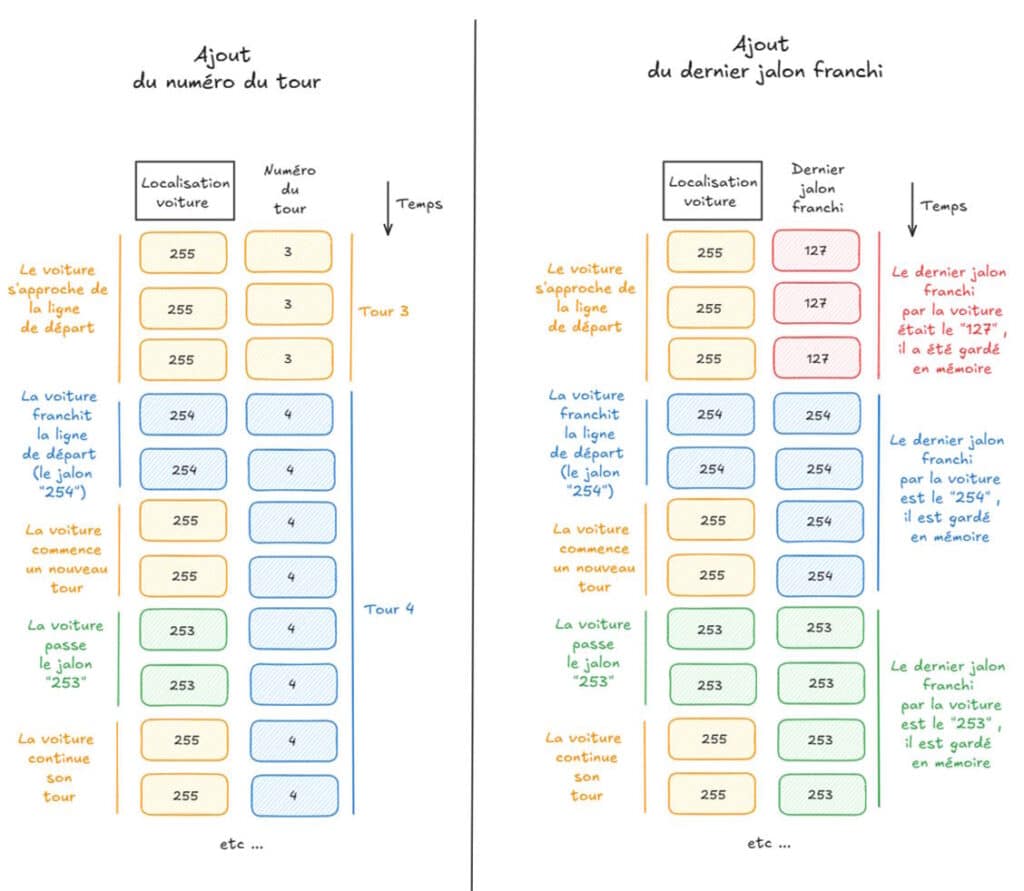
Pour une voiture donnée, la transformation à réaliser est donc la suivante, avec en rouge, les informations que l’on doit rajouter en remontant chronologiquement les données :
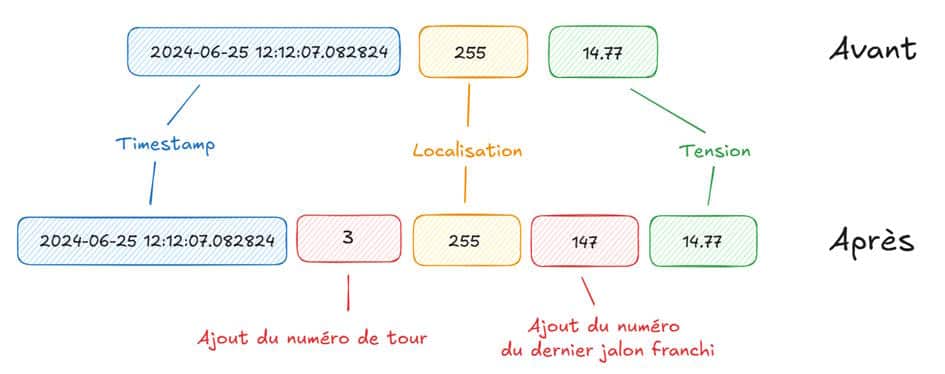
Sur l’exemple schématisé ci-dessus, on constate que la ligne « après transformation » n’est pas directement déductible de la ligne « avant transformation ». C’est ce qui va créer notre problématique par la suite : il y a besoin des lignes précédentes pour réaliser la transformation de données sur la ligne courante.
3. Un ETL qui utilise des technologies parallélisées
Pour bien séparer la logique « collecte des données » de la logique « transformation des données », nous faisons naturellement le choix, initialement, de réaliser les transformations des données dans l’ETL.
Mais quel est notre ETL ? Nous avons choisi un ETL en Scala-Spark, qui transmet ensuite les données à une base de données ClickHouse.
Scala et Spark sont des outils répandus en Big Data (voir par exemple cet article : Pourquoi développer en Spark-Scala ses projets Big Data ?). En ce qui concerne ClickHouse, il s’agit d’une base de données dont nous voulions tester le fonctionnement.
Pour la plupart des calculs que nous avons été amenés à réaliser sur les données, nos outils fonctionnaient très bien. Par exemple, nous avons, avec l’ETL Scala-Spark, appliqué des facteurs multiplicatifs sur certaines colonnes, typé nos données, fait des mappings, agrégé et moyenné certaines grandeurs par section de circuit… Puis nous avons stocké les tables obtenues dans ClickHouse.
Néanmoins, pour l’ajout, sur une ligne de donnée et pour chaque voiture, du numéro du tour et de la section de circuit sur laquelle se trouve la voiture, nous avons rencontré des difficultés. Cela est lié au fait que nous souhaitons réaliser l’ajout en temps réel (les données arrivent en streaming) : nous ne disposons pas de toutes nos données au moment des traitements, mais seulement de celles qui sont déjà arrivées.
L’ETL Scala-Spark n’était tout simplement pas adapté, et ce, pour une raison simple : sa performance repose sur le fait qu’il parallélise les calculs, là où l’ajout des informations sur les tours et les sections de circuit nécessitent, comme nous l’avons vu, de conserver les données en ordre chronologique. La parallélisation des calculs entraîne de facto un mélange des lignes de données, puisque celles-ci sont réparties sur différents nœuds de traitements avant d’être rassemblées.
Nous avons bien essayé de contourner le problème : en numérotant les lignes, en utilisant des window functions, en « forçant » la conservation de l’ordre chronologique… Cela « fonctionnait », dans le sens où nous arrivions aux résultats voulus. Mais cela créait du code compliqué et pas très performant. Finalement, cela en revenait à « tordre » la technologie utilisée, dans une logique très peu adaptée à son fonctionnement normal.
Comment trouver la structure la plus adaptée au projet ?
Nous avons dû nous rendre à l’évidence : nous voulions réaliser des opérations de façon chronologique dans un outil performant, mais qui n’est tout simplement pas profilé pour cela et qui en conséquence ne donne pas de bons résultats pour ce type d’opérations.
Plusieurs options s’offraient alors à nous :
- Changer la technologie utilisée dans notre ETL, c’est-à-dire ne plus utiliser Scala et Spark. Cela aurait été dommage car nous voulions mettre en avant ces technologies qui sont souvent utilisées en Big Data, et qui par ailleurs fonctionnaient très bien et de façon performante pour les autres opérations de transformation des données.
- Réaliser les calculs nécessitant un ordre chronologique après l’ETL, dans ClickHouse. Nous avons essayé et cela n’a pas été plus concluant qu’avec Scala et Spark, car cela compliquait également le code, puisqu’il fallait « remettre en ordre » des données stockées sans ordre. Nous aurions pu tester une base de données davantage orientée time-series. Néanmoins nous voulions éviter de changer nos choix de technologies.
- Réaliser les calculs nécessitant un ordre chronologique avant l’ETL, c’est-à-dire dans la partie « collecte de données ». D’un point de vue logique et organisationnel, c’est un peu moins optimal. Les rôles de chacune des parties du projet sont moins bien séparés les uns des autres quand on réalise des transformations dans la partie « collecte » au lieu de « ETL ». Cependant, si nous effectuons les calculs dès cette phase de collecte, nous profitons du fait que les données arrivent « naturellement » de façon ordonnée temporellement, et nous gagnons ainsi en logique et en simplicité au niveau du code. L’ajout des tours et des sections se fait de façon directe, sans avoir à réordonner quoi que ce soit a posteriori. C’est pourquoi nous avons choisi cette troisième option. Évidemment, cela a alors pour conséquence d’engendrer une modification au niveau de notre partie « collecte des données ».
4. Révision du code Arduino pour ajouter les numéros de tour et les sections de circuit où se situent les voitures
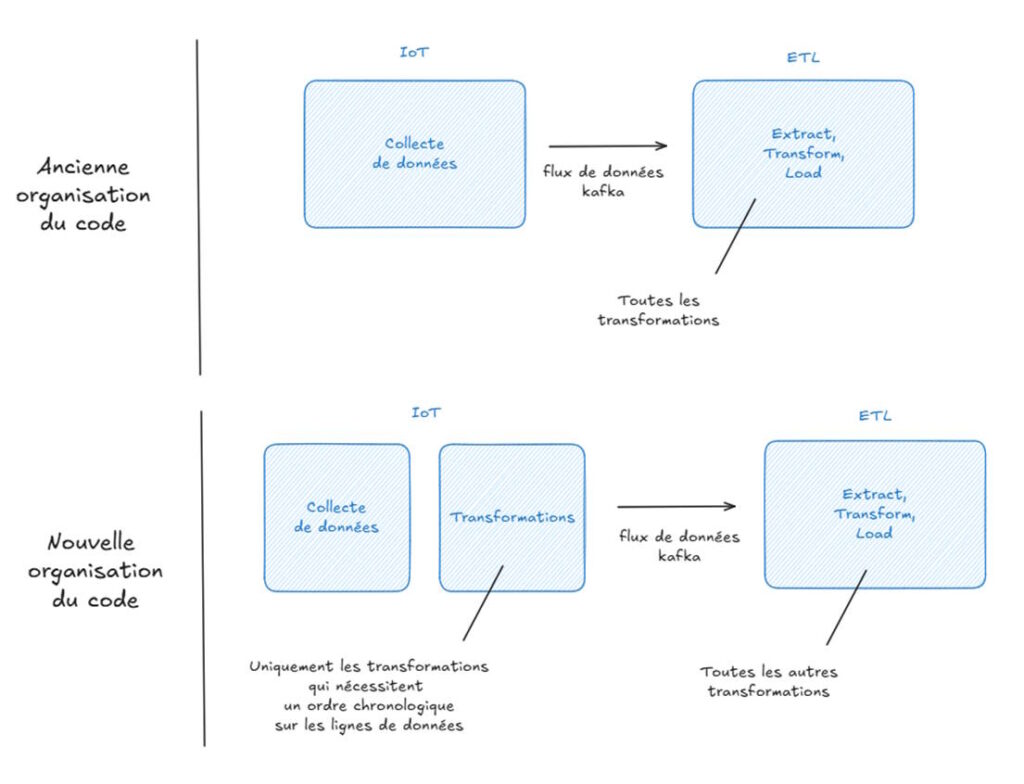
Finalement, c’est notre script Python de la partie IoT qui, après réception des données envoyées par l’Arduino, rajoute les informations voulues sur les lignes de données, avant de les envoyer dans l’ETL pour d’autres transformations. Nous avions tout d’abord pensé à faire les ajouts des tours et de la localisation directement au niveau de l’Arduino, mais cela ralentit les performances de collecte.
C’est donc l’Arduino qui a la fonction de collecte « pure », le script Python qui a la fonction « ajout du timestamp et des informations qui nécessitent un ordre chronologique sur les lignes », et l’ETL Scala-Spark qui a la fonction « toutes les autres transformations qui peuvent se faire de manière parallélisée ». Ainsi les rôles et les performances de chaque partie sont organisées de façon à la fois logique et performante.
Retour sur la partie IA
Il faut aussi ajouter que les données qui remontent de la partie IoT sont non-seulement utilisées par l’ETL, mais aussi par notre IA ! Il était donc important de réaliser certaines transformations dès la partie IoT (comme par exemple, l’ajout du numéro du tour et de la dernière porte franchie), car cela évite alors de recalculer cela deux fois par la suite : dans l’ETL et dans la partie IA.
Le faire en amont fait donc gagner du temps. Finalement, il est intéressant de découper les transformations pour utiliser le bon outil au bon endroit et pour garder ainsi de bonnes performances tout en facilitant les usages !
Conclusion
Nous avons changé plusieurs fois l’organisation de notre code avant d’arriver à la version présentée ci-dessus. Il a été très intéressant de réfléchir à la meilleure structure pour le projet, et en même temps ces changements successifs nous ont donnés du fil à retordre, mais nous sommes maintenant satisfaits de nos performances et de la facilité d’utilisation !
Et vous ?
- Avez-vous rencontré des problématiques similaires ?
- Avez-vous déjà été amenés à remanier d’importantes parties de votre code pour des raisons d’organisation et de performance ?
Dites-le-nous en commentaire !
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn














Commentaire (0)
Votre adresse de messagerie est uniquement utilisée par Orange Business, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Orange Business en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.