Tutoriels outils et langages data
Comment développer et bien exploiter les fonctionnalités des outils et langages Data ?
Requêtage, indexation, agrégation, mise à jour, analyse, etc. Nos experts mettent à votre disposition une approche concrète des possibilités d'application et de déploiements des principaux outils et langages Data, à travers une série de tutoriels.

Comment créer une machine MongoDB avec Vagrant ?
Vagrant est un logiciel permettant d’automatiser la création de machines virtuelles. Par défaut, Vagrant utilise Virtualbox mais il est possible de déployer les machines virtuelles sur d’autres fournisseurs comme VMWare, HyperV, KVM, AWS ou même Azure. Vagrant fonctionne sur la plupart des systèmes d’exploitation. Pour ma part, je dispose d’une machine sous macOs. J’ai donc…

Premiers pas avec Zeppelin
Zeppelin est le compagnon idéal de toute installation Spark. Ce notebook permet de faire des analyses interactives au travers d’un navigateur web. Zeppelin permet d’exécuter du code Spark et de visualiser les résultats dans des tableaux ou graphiques.

Miss France : quelle miss aurait été élue sur Twitter ?
L’élection Miss France génère nombre de commentaires sur les réseaux sociaux, notamment sur Twitter. Ces contenus offre de nombreuses possibilités d'analyse pour répondre à la question : « Quelle Miss aurait été élue par Twitter ? »
![[Tutoriel] Démonstration de la Data Platform d'Hortonworks](https://perspective.orange-business.com/wp-content/uploads/2015/09/Hortonworks-HDP-Platform-Architecture.png)
Démonstration de la Data Platform d’Hortonworks
Comment utiliser MapReduce, Hive, Pig et HCatalog sur la Data Platform d'Hortonworks. Ce tutoriel vous propose de poursuivre l'exploration concrète des outils Big Data à travers la mise en œuvre de la Data Platform d'Hortonworks.
Tutoriel MapReduce
Une approche concrète du développement Big Data avec MapReduce de manière simple pour analyser des données stockées sur hdfs.

Vos vacances avec les Data Heroes – spécial Tutoriel !
Cette semaine, les Data Heroes, et en particulier Stéphane Walter, auteur du Blog Big Data & Digital, vous proposent de revenir sur les outils du Big Data. Voici des extraits choisis : Trois tutoriels pour démarrer avec Hadoop On trouve énormément d’articles sur le Big Data mais il est parfois frustrant de n’aborder que les concepts.…
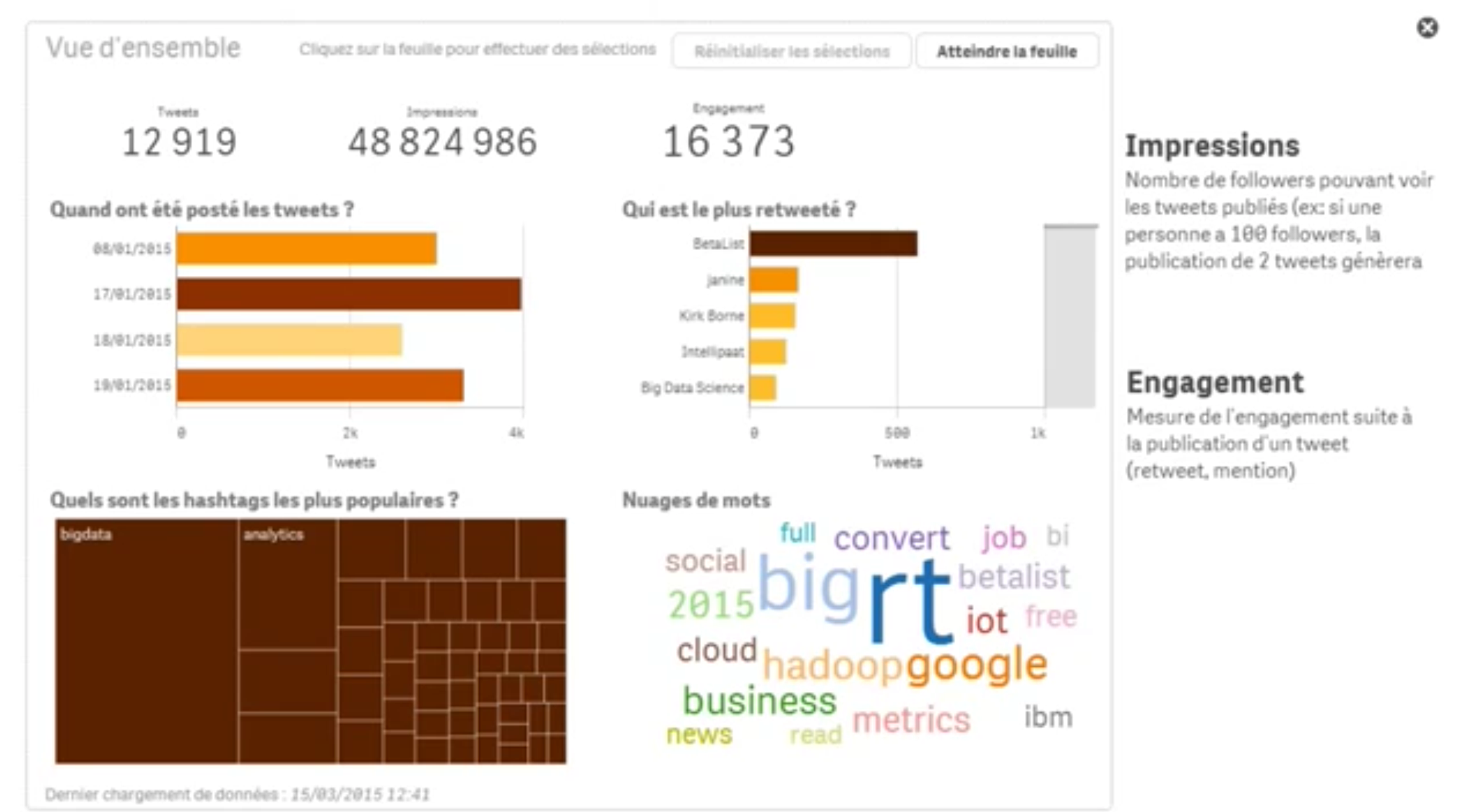
Tutoriel: visualiser les données twitter avec Qlik Sense
Après avoir vu dans l’article précédent comment récupérer les données Twitter avec Flume et Hive, j’ai voulu aller jusqu’à la visualisation des données. Pour se faire, j’ai utilisé Hive pour calculer quelques indicateurs de sentiment. Le principe repose sur l’utilisation d’une table de mots clés classés comme positif, neutre ou négatif. Il suffit ensuite d’analyser la syntaxe (dans…

Analyser les données Twitter avec Flume et Hive
L’objectif de ce tutoriel est de vous montrer comment utiliser Flume et Hive pour analyser des données en provenance de Twitter. Il a également pour objectif de mettre en évidence les difficultés que l’on rencontre actuellement avec des plateformes Big Data en évolution rapide mais pas toujours stabilisées, d’où l’importance de disposer d’une expertise suffisante…

Installer soi-même un cluster Hadoop (1 nœud)
Vous avez sûrement lu de nombreux articles sur Hadoop et vous souhaitez maintenant vous familiariser avec. Mais comment faire pour apprivoiser cette nouvelle technologie ? L’approche recommandée consiste à installer une machine virtualisée fournie clé en main par les principaux éditeurs de distribution. Une autre approche, plus technique, consiste à installer soi-même Hadoop sur une seule machine (cluster…

Trois tutoriels pour démarrer avec Hadoop
On trouve énormément d’articles sur le Big Data mais il est parfois frustrant de n’aborder que les concepts. Certaines personnes, comme moi, ont besoin de visualiser les outils pour appréhender de nouvelles technologies. A cette fin, j’ai compilé 3 courtes vidéos sur Hadoop pour démystifier la chose. Les exemples sont tirés d’un POC (Proof of…